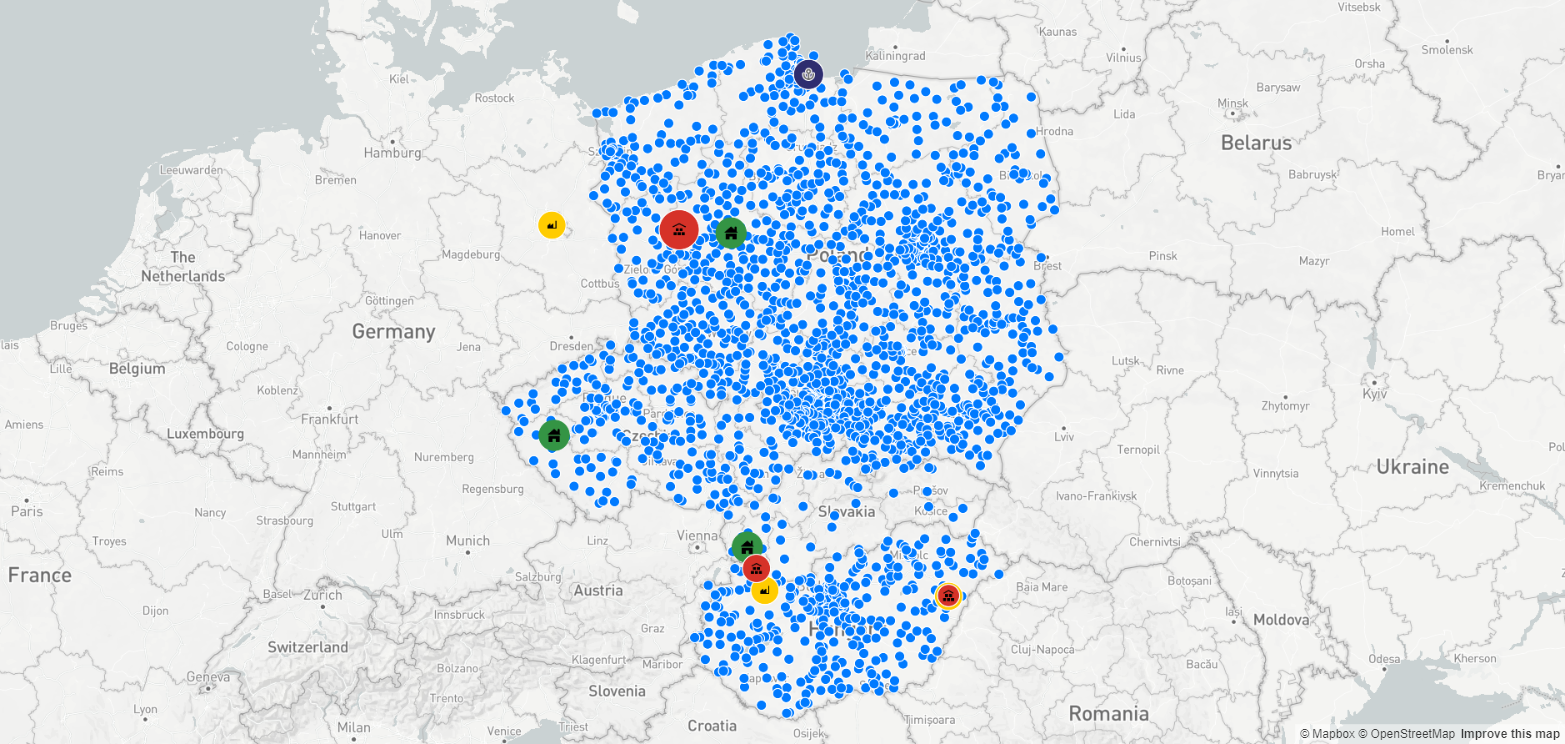
Jak można się było spodziewać, wskazania optymalnych lokalizacji magazynowych są zupełnie inne. Widzimy też, że lokalizacje DC znajdują się bezpośrednio przy źródłach pochodzenia produktów (fabryki lub dostawcy kluczowi). Wynika to z tego, że wolumen produktów wysyłany od dostawców jest nieporównywalnie większy, niż wolumen dostarczany do poszczególnych pojedynczych odbiorców.
Jest jedna bardzo ważna kwestia, o której należy pamiętać przy obliczeniach środków ciężkości: wskazanie optymalnej lokalizacji odbywa się na podstawie lokalizacji dostawców i odbiorców oraz danych wolumetrycznych. Kalkulacja środka ciężkości nie uwzględnia kosztów transportu od dostawców do magazynów oraz dystrybucji z magazynów. Ponieważ na ogół koszty transportu do magazynów w przeliczeniu na jednostkę towaru są dużo niższe niż koszty dystrybucji, możemy przeprowadzić analizę środków ciężkości z pominięciem dostaw. Przy założeniu, że interesują nas trzy centra dystrybucyjne, mapa łańcucha dostaw będzie przedstawiać się następująco:
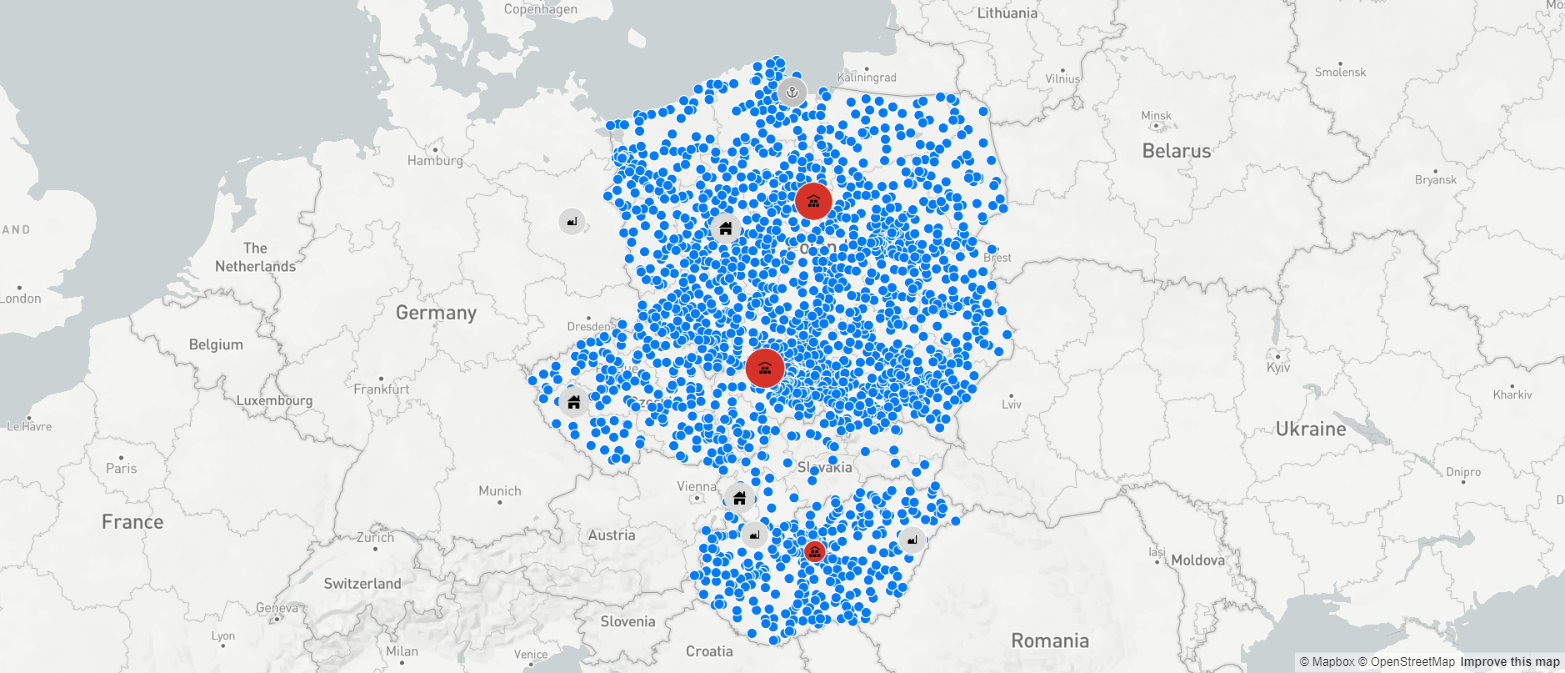
Czerwone punkty na mapie oznaczają lokalizacje centrów dystrybucyjnych przy założeniu, że pod uwagę zostały wzięte tylko dane dystrybucyjne (dostawcy i zakłady produkcyjne zostały zaznaczone kolorem szarym, ponieważ nie były brane pod uwagę). W tym wypadku mediana odległości z centrów dystrybucyjnych wynosi ok. 145 km, a najdalszy dystans między DC a odbiorcą to 403 km. Aplikacje umożliwiają nam też wizualizację zasięgów i odległości:
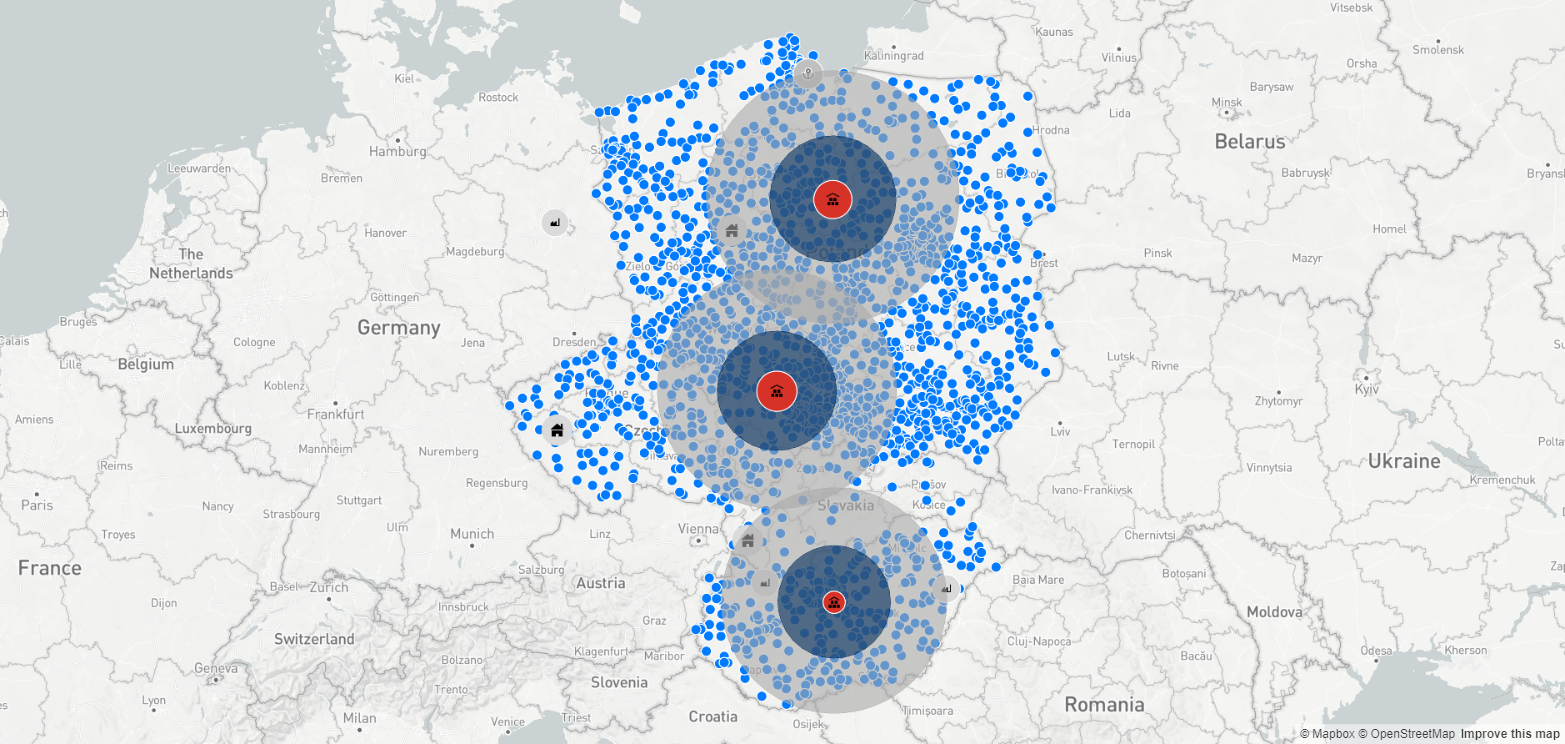
Kręgi wokół centrów dystrybucyjnych oznaczają obszary w promieniu 180 km w linii prostej, co jest raczej maksymalnym lub bliskim maksimum dystansem biorąc pod uwagę fakt, że samochody dystrybucyjne dostarczają produkty do kilku – kilkunastu odbiorców dziennie, a po zakończeniu trasy wracają do danego DC.
Powyższa mapa wskazuje na to, że nawet trzy centra dystrybucyjne, czy też platformy dystrybucyjne nie zapewnią sprawnej dystrybucji. Ponadto, jak wspomniano wcześniej, analizy środka ciężkości nie uwzględniają niezmiernie ważnej kwestii projektu, jaką są koszty.
Aby wyznaczyć naszą sieć dystrybucyjną możemy użyć innej funkcji – Supply Chain Applications, która pozwoli na wyznaczenie właściwych miejsc dla magazynów, na podstawie ich lokalizacji, kosztów magazynowych, kosztów transportu od dostawców do magazynów i kosztów dystrybucji. Ponadto dodatkowa funkcjonalność aplikacji pozwala nam na wyznaczenie maksymalnej odległości pomiędzy wskazanymi centrami dystrybucyjnymi lub platformami przeładunkowymi a odbiorcami. Dla tego celu musimy jednak stworzyć listę potencjalnych lokalizacji magazynowych, z których aplikacje wyznaczą te optymalne pod względem kosztowym.
Takie zadanie jest już nieco bardziej skomplikowane i wymaga od użytkownika przygotowania większego zasobu danych niż tylko dane wolumenowe per odbiorca lub nadawca. Aby zrealizować zadanie będą nam potrzebne:
- koszty transportu z fabryk, portu i od dostawców do potencjalnych lokalizacji magazynowych – albo w ujęciu kosztu za 1 km albo kosztów za daną trasę – oraz dane dotyczące ładowności dostępnej floty samochodowej (dla uproszczenia założymy, że wszystkie zakłady produkcyjne i dostawcy zaopatrują magazyny samochodami o ładowności 24 t i kubaturze netto 70 m3, a z portu w Gdańsku dostawy są wysyłane z kontenerami morskimi o ładowności 20 t i kubaturze netto 50 m3),
- pula lokalizacji magazynów branych pod uwagę wraz z ich lokalizacjami geograficznymi, ich koszty stałe i koszty obsługi przeładunków per kg lub metr sześcienny (może być zestaw obu danych, lub tylko jeden z kosztów, w zależności od danego „business case”),
- informacje o rodzaju floty samochodowej i kosztach dystrybucji z danych magazynów do odbiorców – ponieważ aplikacja daje możliwość założenia tylko jednego typu samochodu dla dystrybucji „ostatniej mili”, przyjmijmy roboczo, że samochody dystrybucyjne będą miały ładowność 10 t/40 m3,
- maksymalna odległość między magazynami a odbiorcami – ten parametr może być wspólny dla wszystkich magazynów, może być też ustalony indywidualnie dla każdego magazynu osobno.
Posiadając powyższe dane możemy przeprowadzić symulację w Supply Chain Applications. Przed jej rozpoczęciem możemy zadać parametry bazowe, takie jak minimalna i maksymalna liczba magazynów, maksymalna odległość między magazynami a poszczególnymi klientami, multi – sourcing, czyli możliwość zaopatrywania jednego magazynu przez wielu dostawców lub zakładów produkcyjnych. Możemy też wskazać opcję zaopatrywania danego odbiorcy produktami pochodzącymi od danego dostawcy lub z danego zakładu produkcyjnego.
Dla potrzeb tego artykułu przyjęto następujące potencjalne lokalizacje magazynowe:
- Polska: Warszawa, Łódź, Wrocław, Katowice, Kraków, Gdańsk, Bydgoszcz, Białystok, Rzeszów, Lublin, Szczecin, Poznań, Zielona Góra, Olsztyn i Koszalin,
- Czechy: Praga, Pilzno, Ostrawa, Brno, Liberec i Zlin,
- Słowacja: Bratysława, Koszyce, Żylina, Bańska Bystrzyca i Nitra,
- Węgry: Budapeszt, Györ, Debreczyn i Kecskemet.
Aby symulacja sieci dystrybucyjnej była jak najbardziej obiektywna, wszystkim dostawcom i fabrykom oraz wszystkim magazynom przypisane zostały identyczne warunki kosztowe. Ponieważ aplikacja sama może obliczyć i wskazywać określone lokalizacje magazynowe, zostawiliśmy pełną dowolność obliczeń, co poskutkowało tym, że narzędzie samo wskazało właściwe lokalizacje magazynów. Jedynym warunkiem postawionym przed aplikacją była maksymalna odległość między wskazanymi magazynami a klientami, określona na poziomie 300 km.
Oto mapa przedstawiająca dane wynikowe:
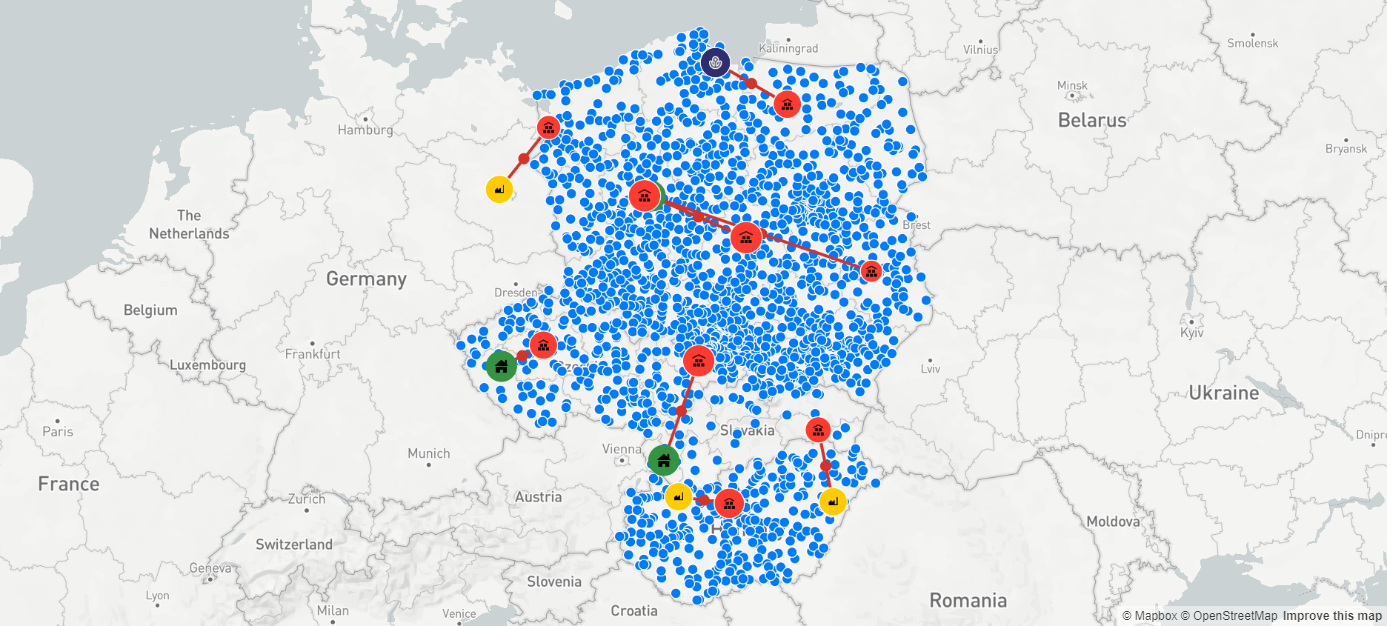
Nasze narzędzie wskazało 9 optymalnych lokalizacji magazynowych: Olsztyn, Szczecin, Poznań, Łódź, Lublin w Polsce, Pragę i Ostrawę w Czechach, Koszyce na Słowacji oraz Budapeszt na Węgrzech. Zielone linie między dostawcami, zakładami produkcyjnymi a wskazanymi centrami dystrybucyjnymi oznaczają, które centra dystrybucyjne powinny być zaopatrywane przez poszczególnych dostawców.
Jeśli wyznaczymy narzędziu inny limit odległości maksymalnej między magazynami a klientem, wskazania lokalizacji magazynów będą przedstawiać się inaczej, co widać na poniższym przykładzie:
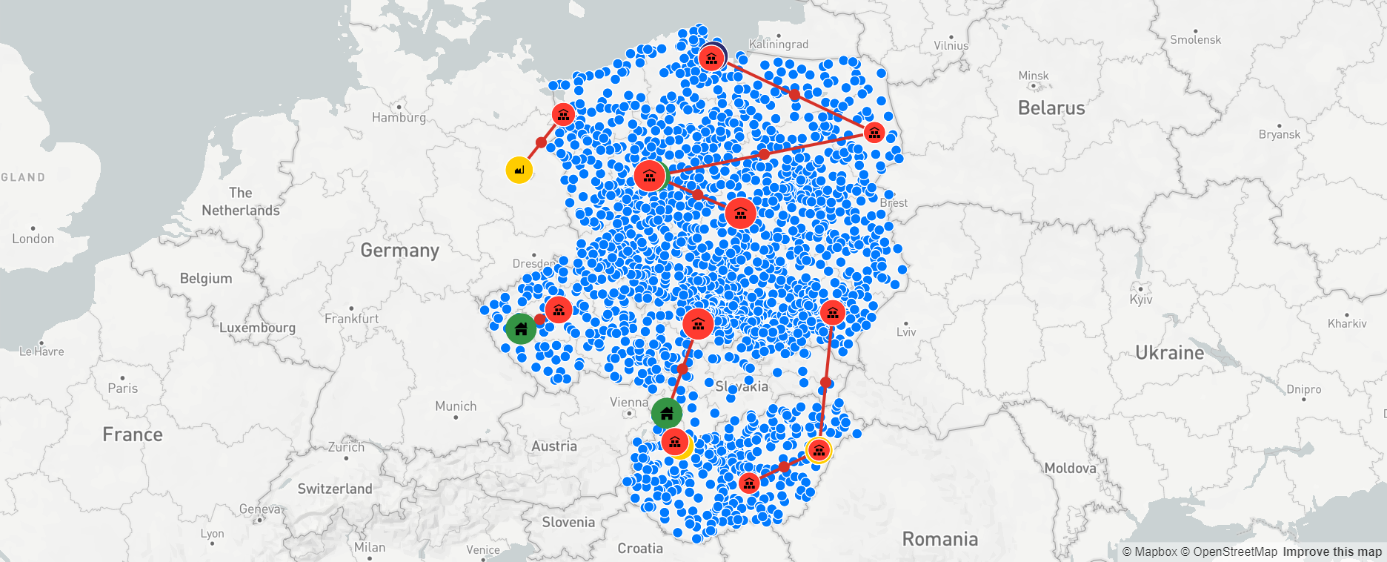
Porównując nowe wskazanie aplikacji widzimy, że sieć magazynów uległa zagęszczeniu, a niektóre lokalizacje zostały zastąpione innymi. Obecne wskazania lokalizacji to: Gdańsk, Szczecin, Białystok, Poznań, Łódź, Rzeszów, Praga, Ostrawa, Györ, Kecskemet i Debreczyn.
Wyznaczając sieć dystrybucyjną warto zweryfikować, czy będzie ona faktycznie funkcjonować. Można to zrobić na przykład podczas wskazanie zasięgów dystrybucji z danych centrów dystrybucyjnych przy założeniu określonej liczby kilometrów z danej platformy dystrybucyjnej. Poniższa mapa pokazuje pokrycie Polski, Czech, Słowacji i Węgier z wyznaczonych 11 platform dystrybucji przy założeniu, że zasięg dystrybucji z każdego magazynu wynosi 135 km w linii prostej, czyli ok. 175 km po drogach:
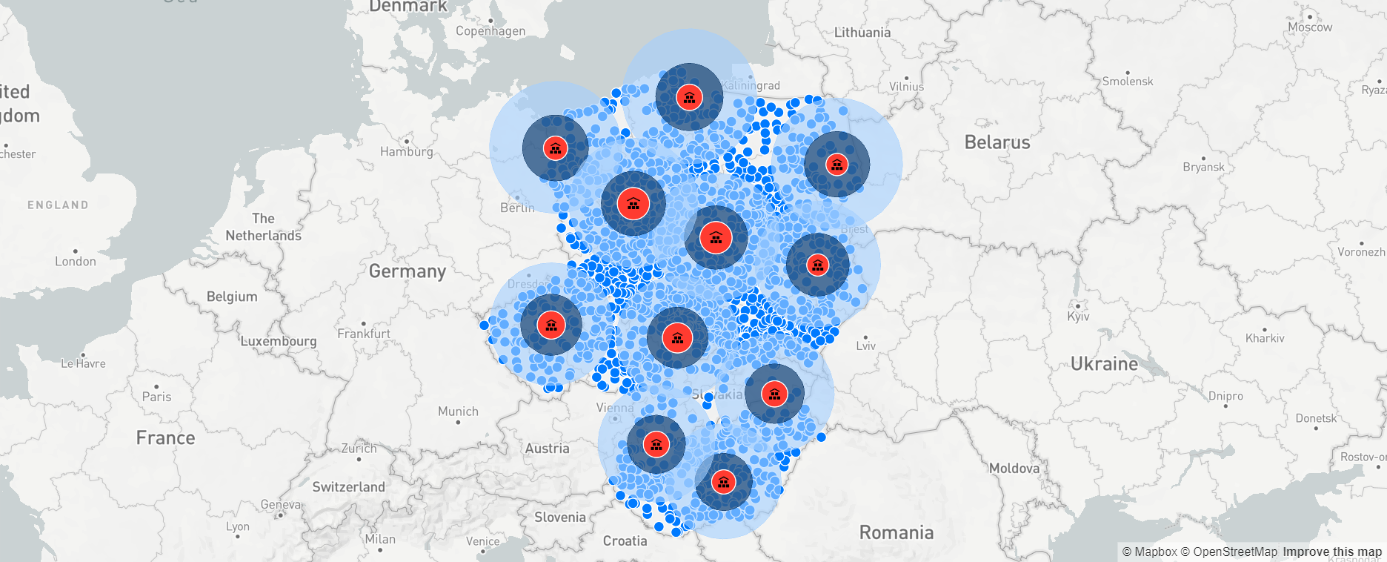
Mapa wskazuje na to, że ogromna większość odbiorców leży w zasięgu dystrybucji ustalonej przy wybranych parametrach.
Istnieje również możliwość wskazania stałych magazynów, które w wyniku określonego kontekstu biznesowego muszą stanowić elementy naszej sieci dystrybucyjnej. Ponieważ rozważane do tej pory warianty sieci dystrybucyjnej nie uwzględniły magazynów w Warszawie ani w Katowicach, przeprowadźmy ponownie symulację sieci z tymi dwoma lokalizacjami wskazanymi jako stałe.
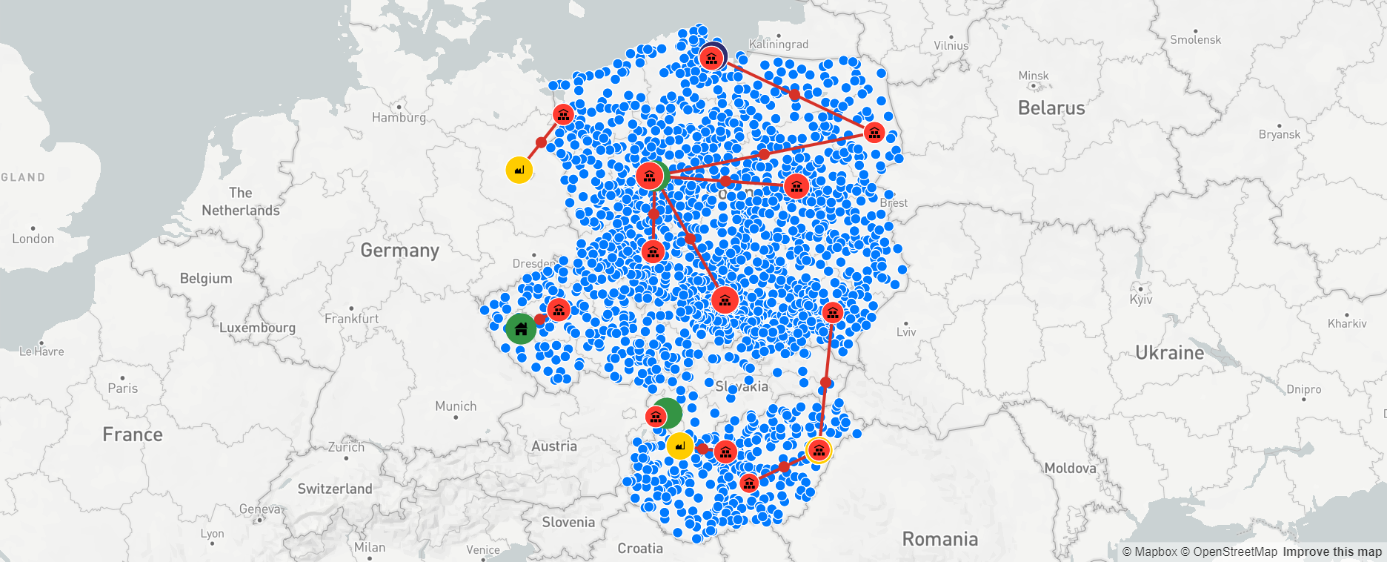
Jak widzimy, wyznaczenie magazynów w Warszawie i Katowicach jako magazynów stałych miało dość spory wpływ na naszą sieć dystrybucyjną: wzrosła łączna liczba magazynów z 11 do 13 (parametr maksymalnej dopuszczalnej odległości od platformy dystrybucyjnej do odbiorców na poziomie 250 km został zachowany), zaś niektóre wcześniej występujące lokalizacje nie pojawiły się już na mapie naszego łańcucha dostaw.
Możemy porównać wyniki wskazań trzech przeprowadzonych iteracji, czyli symulacji łańcucha dostaw, z uwzględnieniem nieco innych parametrów:
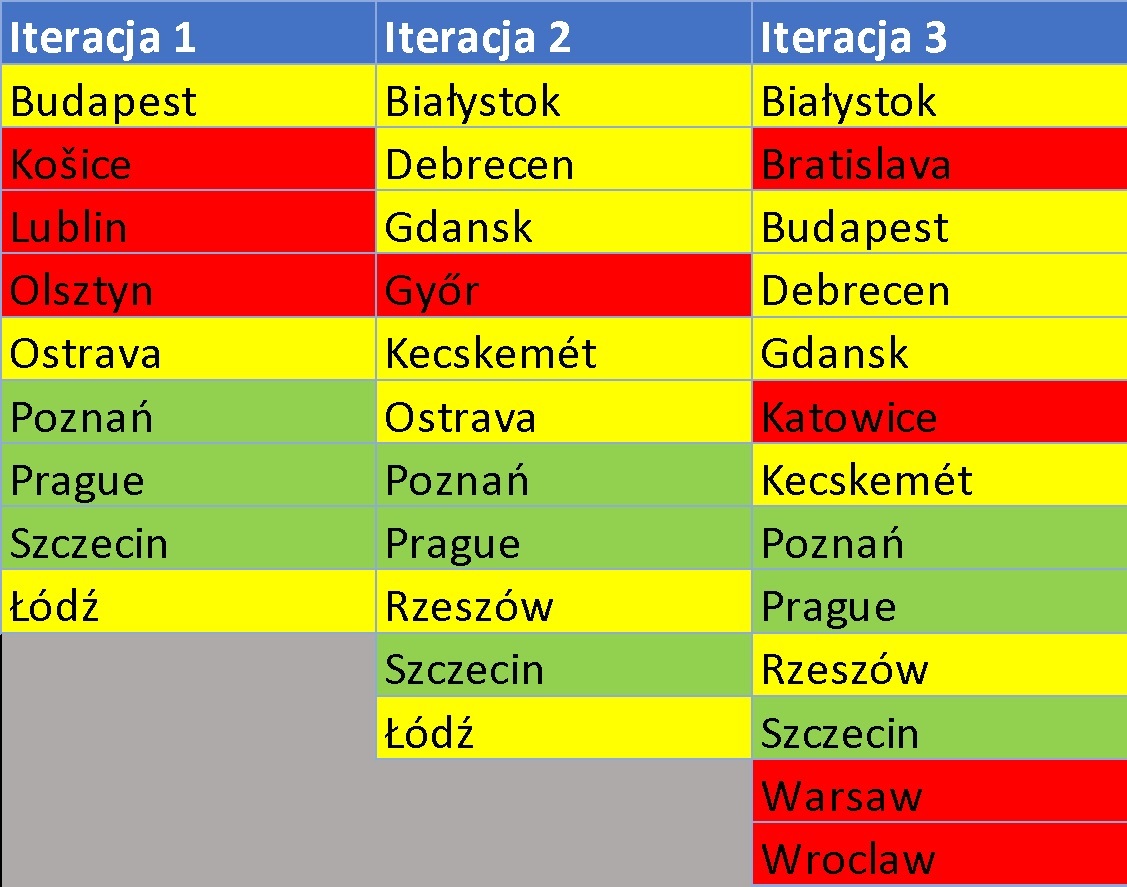
Kolorem zielonym zaznaczono lokalizacje wskazane przez wszystkie trzy symulacje, na żółto lokalizacje występujące w dwóch iteracjach a na czerwono – tylko w jednej.
Przypomnijmy reguły iteracji:
Iteracja 1: Supply Chain Applications miało wskazać optymalne lokalizacje przy założeniu, że maksymalna odległość między magazynem a odbiorcą nie może przekraczać 300 km. Żadna lokalizacja nie została wskazana jako stała.
Iteracja 2: Narzędzie miało wskazać optymalne lokalizacje przy założeniu, że maksymalna odległość między magazynem a odbiorcą nie może przekraczać 250 km. Żadna lokalizacja nie została wskazana jako stała.
Iteracja 3: Narzędzie miało wskazać optymalne lokalizacje przy założeniu, że maksymalna odległość między magazynem a odbiorcą nie może przekraczać 250 km, przy czym lokalizacje platform dystrybucyjnych w Warszawie i Katowicach zostały wskazana jako konieczne do uwzględnienia.
Pakiet omówionej aplikacji SCA Log-hub zawiera jeszcze inne funkcje przydatne przy planowaniu strategicznym. Bardzo ciekawą opcją jest Supply Chain Simulator, który porównuje koszty scenariuszy łańcucha dostaw przy uwzględnieniu dystrybucji poszczególnych SKU, stanów magazynowych oraz różnych opcji lokalizacji dostawców oraz magazynów. Ale to już jest temat na osobny artykuł.













